Vieleicht war das gar nicht die Motivation, sondern, dass keine Diktatur Zugriff auf die Daten ihrer Bürger erhält (Wahrscheinlich inclusive der Standortdaten).
Manchmal würde ich mir das von unserer Regierung auch wünschen!
Von OpenAi bezweifel ich, dass es was offline geben wird, aber es wird sicher ein Modell kommen bei dem das funktioniert. Die Ansätze sind ja schon da.
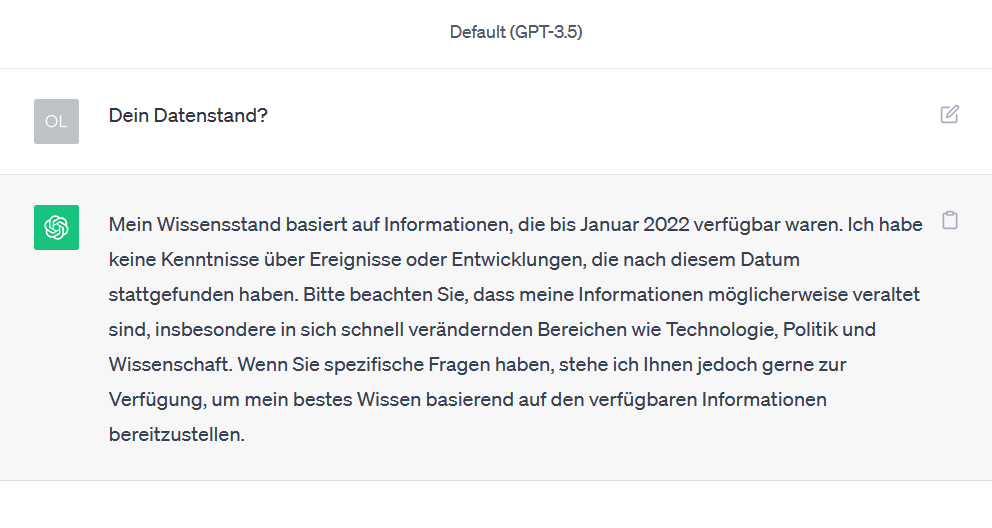
Was allerdings das Datensammeln angeht, sollten wir uns nicht an Mutmaßungen halten (Microsoft hält 49% an OpenAI, also ist ChatGPT des Teufels). Sondern an Tatsachen: Aktuell ist die kostenlose Variante auf einen Datenbestand bis zum September 2021 beschränkt (dieses Limit gilt nicht mehr für die kostenpflichtige Version). Sie lernt nicht dazu, außer innerhalb eines individuellen Chats. Wenn der Nutzer den Chat löscht, sind die entsprechenden Daten, die er zu diesem Chat beigetragen hat, nach spätestens 30 Tagen gelöscht.
Kurzfassung: Wenn die Deutsche Bahn, das Zweite Deutsche Fernsehen oder die Hamburger Stadtreinigung mit ihren Websites und Online-Services so datenschutzfreundlich wären, wie es aktuell ChatGPT 3.5 ist, könnten wir jubeln.
Es wäre blauäugig zu glauben, das die Daten nicht benutzt werden ihr Modell zu verbessern. Und dazu die Informationen ggf. wieder generierbar zu machen.
Dass OpenAI personenbezogene Daten speichert, wenn man beim Anlegen des Accounts Echtdaten eingibt, stimmt selbstverständlich – macht man halt nicht.
Und die Eingaben, die der Nutzer von ChatGPT in Chats macht, werden aktuell nicht standardmäßig in den Datenbestand übernommen – genießen aber andererseits keine generelle Zusage von Vertraulichkeit. Das ist der Grund, warum bei jedem Einloggen in ChatGPT ein Warnfenster aufpoppt: Don’t share sensitive Info. Chat history may be reviewed … Deswegen verbietet sich der professionelle Einsatz für Berufsgeheimnisträger wie Anwälte, Ärzte, Priester tatsächlich.
Überhaupt sind sie groß im Warnen: Check your facts. While we have safeguards ChatGPT may give you inaccurate information.
Wenn solche Hinweise auf Risiken und Nebenwirkungen üblich wären, hätten wir schon viel gewonnen.
Ich denke, man tut gut daran, davon auszugehen, daß AI/KI immer dazu lernt, wenn es an zusätzliche Informationen gelangt – egal, ob es im Einzelfall zutrifft.
Einerseits ist sie naturgemäß „süchtig“ danach, andererseits sind die Entwickler dieser Technik höchst interessiert daran und in der Regel keineswegs vertrauenswürdig.
Das ist definitiv so: Was sich so KI nennt, lebt nur von der Qualität der Algorithmen und der Quantität der Daten. Deswegen hab ich ja auch vorsichtig eingeschränkt, das ChatGPT 3.5 aktuell weitgehend harmlos ist.
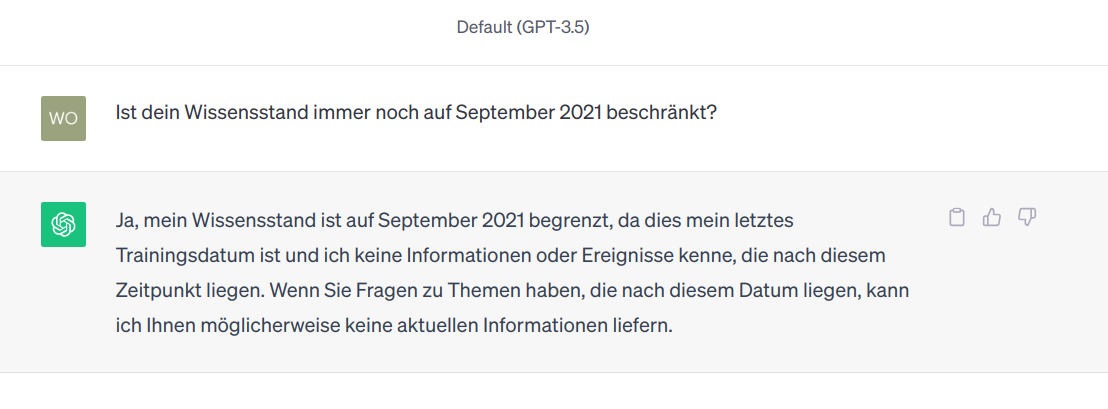
ChatGPT dazu: „Ja, mein Wissensstand ist auf September 2021 begrenzt, da dies mein letztes Trainingsdatum ist und ich keine Informationen oder Ereignisse kenne, die nach diesem Zeitpunkt liegen. Wenn Sie Fragen zu Themen haben, die nach diesem Datum liegen, kann ich Ihnen möglicherweise keine aktuellen Informationen liefern.“
Und jetzt die spannende Frage: Wen von uns beiden lügt ChatGPT an? Und warum?
[Zusatz]
Na gut, die Antwort kann ich selber geben: mich. Denn im Gegensatz zu dir hab ich mit der Vorgabe „September 2021“ die unrichtige Antwort getriggert. Wahrscheinlichkeitsbasierte Chatbots sind eben auch nur Menschen …
Ob das dann auch für KI Grundtexte und menschlich verfeinerte Texte gilt, wird sich zeigen. Zumindest von Behörden, denke ich, werden wir dann gesetzestreu häufiger in Zukunft lesen wie z.B. „Dieser Text wird Ihnen präsentiert von XYZ“ oder so
Wenn es um journalistische Texte geht, bin ich da hin & her gerissen. Zwar habe ich viele Jahre als Journalist in einem großen Medienkonzern gearbeitet, aber mittlerweile kommt bei mir der Verdacht auf, KI könnte differenziertere Berichterstattung leisten als die Mitarbeiter der etablierten Medien.
Beispiel: Ich habe mal spaßeshalber ChatGPT mit einem Statement des ehemaligen US-Präsidenten Jimmy Carter von 2019 konfrontiert – Carter hatte damals darauf hingewiesen, dass die USA in ihrer 242jährigen Geschichte nur 16 Jahre keinen Krieg geführt habe. Der amerikanische Chatbot hat sich mit seinem abwiegelnden Kommentar dazu definitv geschickter geschlagen, als ich es mittlerweile aus Bild, Spiegel, taz oder öffentlich-rechtlichem Fernsehen gewohnt bin.
Das kann auch bei Printmedien schiefgehen und zwar ohne KI: Vor Jahren wurde im Spiegel mal wieder die Barschel Affäre aufgewärmt, insbesondere die Frage ob es Mord oder Selbstmord war. Und auf einer Seite des Artikels fand sich auch Werbung eines Herstellers für Badewannen.
Darf ich fragen wie (App/Browser) Du ChatGPT nutzt und wofür (Suchmaschinen ersatz/Wissenschftliches Interesse/Arbeit/etc.) und ob/wie Du es geschafft hast die Telefon Zertifizierung überlisten?
Der Grund, ich bin und werde immer unzufriedener mit den Ergebnissen diverser Suchmaschinen, die alles auswerfen nur nicht das wonach gesucht wird und würde das gerne mal ausprobieren ob mir hier geholfen wird, sehe es aber nicht ein meine Telefonnummer dafür raus zu rücken.
Also für 3.5 musst du keine Telefonnummer angeben. Ich nutze das nur im Browser, den ich ausschließluch für ChatGPT nutze. Sprichst du von 4.0? Ansonsten evtl. mal Braves Leo testen?
Ich spreche von dieser Seite hier → https://chat.openai.com/auth/login
welche mich nach cloudflare Proxy klicke ich bin doch blöd
zu diesem Bildschirm führt wo man auch darauf hingewiesen wird eine Nummer natürlich nur für die eigene Sicherheit angeben zu müssen.
Was die Telefonnummer angeht, hat Alawari ja schon den entscheidenden Tip gegeben. Und wofür ich ChatGPT nutze? Eigentlich nur, um so ein wahrscheinlichkeitsbasiertes großes Sprachmodell zu testen, also nicht in der täglichen praktischen Anwendung.
Obwohl du natürlich Recht hast: Suchmaschinenergebnisse werden durch die Bank weniger brauchbar, dafür sorgen kommerzielle (und mehr und mehr auch politische) Interessen.